강화학습 특징

- 답을 알려주는 사람(supervisor)이 없고 오로지 보상(reward)만 존재한다.
- 피드백(Feedback)이 즉시 전달되는 것이 아닌 지연된다.
- 시간 요소가 매우 중요하다. (독립적인 데이터(i.i.d)가 아닌 시계열의 데이터이기 때문에 앞뒤 시간의 데이터가 연관성을 갖는다.)
- 에이전트(Agent)의 행동이 받게되는 데이터에 영향을 준다.
보상(Rewards)

- Reward Hypothesis 정의 : 모든 목표는 누적 보상(cumulative reward)의 기대값이 최대로 하는 방향으로 표현할 수 있어야 한다.
- cumulative reward : 강화학습을 진행하면서 얻게되는 보상의 합계
- 보상이 최대가 되는 방향으로 진행하면 목표가 달성될 수있어야 한다.
- 보상(Reward, Rt )은 스칼라(Scalar) 형태의 피드백(feedback)이다
순차적인 의사 결정 (Sequential Decision Making)
- 목표(Goal) : Select actions to maximise total future reward
- 미래의 보상의 합계가 최대가 되도록 행동(Actions)을 선택하는것을 목표로 한다.
- 행동(Actions)은 매우 긴 결과(long term conseqeunces) 를 가질 수 있다.
- e.g. 에피소드가 종료되지 않고 길어질수도 있는 등
- 보상(Rewards)은 지연될 수 있다.
- e.g. 길찾기 문제에서 목표에 도달하면 보상이 주어진다고 할때 목표점에 도달하지 못하면 도달할 때까지 보상을 받지 못함.
에이전트(Agent)와 환경(Environment)

- 에이전트(Agent)는 복잡한 동적인 환경내에서 행동(Actions)을 실시하여 목표를 달성하려고 시도하는 객체
- 예 : 미로를 빠져나가는 쥐 문제에서 에이전트는 쥐
- 환경으로부터 관측(Observation, Ot)에 대한 정보를 받고 행동(Actions, At)을 결정한다.
- 환경(Environment)은 주로 마르코프 결정과정(MDP)로 표현된다.
- 예 : 미로를 빠져나가는 쥐 문제에서 환경은 미로
- 에이전트의 행동에 따른 보상(Rt)을 에이전트에게 제공한다.
- 관측 결과를 에이전트에게 제공한다.
히스토리(History)와 상태(State)
- 히스토리(History, Ht)는 시간에 따른 관측, 행동, 보상의 집합

- 상태(State, St)는 에이전트가 다음 행동을 결정하기 위해 고려하는 정보들

Information State(Markov State)
- 마르코프 상태(Markov State)는 이전 히스토리에 대한 정보를 모두 포함하고 있다는 것을 의미한다.

- Markov 하다는 뜻은 현재 상태(St)에서 다음 상태(St+1)에 가게 될 확률은 이전 모든 상태(S1, S2, …, St-1)에서 부터 진행되어 현재 상태(St)에 왔을 때 다음 상태(St+1)에 가게 될 확률과 동일하다는 뜻으로, 다음 상태를 고려할 때 현재 상태만 고려하면 된다는 의미이다.
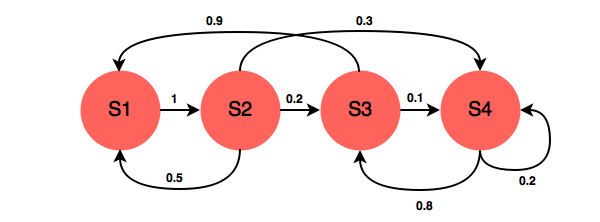
- 예 ) 아래 그림에서 현재 S3상태에 있다고 가정했을시, S3에서 S4로 갈 확률은 0.1이다. S3에 어떻게 해서 도달했는지는 중요하지 않다.
- S3에서 S4에 갈 확률은 이전 히스토리가 어떻게 되었든 0.1이다.
- 경우 1 : S1 → S2 → S3
- 경우 2 : S1 → S2 → S4 → S3
- 두 경우 이외에도 S3에 도달하는 경로(히스토리)는 다양하지만, 어떻게 도달했든 S3에서 S4로 갈 확률은 0.1로 동일하다.
- S3에서 S4에 갈 확률은 이전 히스토리가 어떻게 되었든 0.1이다.
완전 관측(Fully Observable Environment) VS 부분 관측(Partially Observable Environment)
| Fully Observable Environment | Partially Observable Environment |
|
|
8. 강화학습 에이전트(RL Agent)의 구성 요소
- 정책(Policy)
- 정책은 에이전트의 행동을 결정하는 함수이다.
- 가치 함수(Value Function)
- 가치 함수는 에이전트의 상태(S)나 행동(A)이 얼마나 좋은지를 도출하는 함수이다.
- 모델(Model)
- 환경에 대한 에이전트의 표현이다.
- 정책, 가치함수, 모델의 설정에 따라 강화학습은 다음 그림과 같이 분류할 수 있다.

※ 해당 내용은 David Silver 교수님의 Introduction to Reinforcement Learning 강의를 기반으로 강화학습에 대하여 정리한 자료입니다.
- 강의 영상(Lecture) : https://www.youtube.com/watch?v=2pWv7GOvuf0&list=PLqYmG7hTraZDM-OYHWgPebj2MfCFzFObQ
- 강의 슬라이드(Slide) : https://www.davidsilver.uk/teaching/



댓글